

Testujemy strategie od ChataGPT – czy AI pomoże Ci zarabiać na giełdzie?
ChatGPT generuje grafiki, pisze oprogramowanie i artykuły czy analizuje dane. I wszystko to, przynajmniej na pierwszy rzut oka, robi dobrze. Szybko pojawiły się więc pomysły budowania strategii tradingowych za jego pomocą. Bo skoro AI wie wszystko, to może i zna sekret zarabiania na rynku? Niestety w praktyce sprawa nie jest tak prosta, jak się wydaje.
Czy ChatGPT napisze za nas system tradingowy?
Aby sprawdzić w praktyce zdolność ChataGPT do budowy strategii (zdolność, która jest dzisiaj promowana przez twórców YouTube i sprzedawców kursów), poprosiłem model o podsunięcie mi pomysłów na systemy tradingowe z trzech grup: dla początkujących, średnio zaawansowanych i zaawansowanych.
Model zaproponował trzy rozwiązania:
- Dla początkujących: Strategia SMA Crossover (kupno/sprzedaż po przecięciu prostych średnich kroczących).
- Średnio zaawansowana: RSI + Price Action (rozgrywanie poziomów overbought i oversold).
- Zaawansowana: Momentum + Volatility Regime Filter (ATR) – kupno po wzrostach z wyłączeniem okresów o wysokiej zmienności.
W praktyce każdy z powyższych pomysłów jest przeznaczony dla początkujących lub w najlepszym wypadku – średnio zaawansowanych traderów. Chociaż ostatnia strategia próbuje filtrować okresy wyższej zmienności za pomocą ATR, jest to narzędzie początkującym traderom znane dosyć dobrze. Plusem jest, że model zaproponował wykorzystanie Momentum, które czasem faktycznie bywa implementowane w realnych systemach tradingowych.
Niemniej nie ma tu jednak pomysłów zaawansowanych statystycznie czy mających głębsze uzasadnienie ekonomiczne. Po prostu – stara, dobra, analiza techniczna.
Przymiotnik “dobry” należy tu jednak wziąć w cudzysłów, ponieważ tego typu metody są znane w środowisku ze swojej nieskuteczności. Przecięcia średnich kroczących najczęściej są narzędziem, które nieźle radzi sobie w trendach kierunkowych i oddaje wszystkie zyski w trendach bocznych. Z RSI jest odwrotnie – działa w trendach bocznych i staje się maszynką do tracenia pieniędzy gdy rynek osiądzie w balansie.
Nie dość, że Hipoteza Rynku Efektywnego udowadnia, że bicie indeksów to zadanie trudne, łamane przez “niemożliwe”, bot nie zaproponował nam nic nowego. Żeby wyciągnąć z niego pomysły nieco bardziej sensowne, trzeba samemu wiedzieć, czego dokładnie szukamy.
Strategia dla początkujących: przecięcia średnich kroczących
Przejdźmy jednak do wyników. Po otrzymaniu kodu dla wszystkich strategii poprosiłem model o porównanie wyników backtestingu z klasycznym Buy&Hold na indeksie S&P500. Pierwszy system – oparty na średnich kroczących, od 2010-01-01, zgodnie z przypuszczeniami, wygenerował 28.47% straty. W tym samym czasie trzymanie w portfelu indeksu S&P500 (ticker ^GSPC) dało 449.87% zysku.
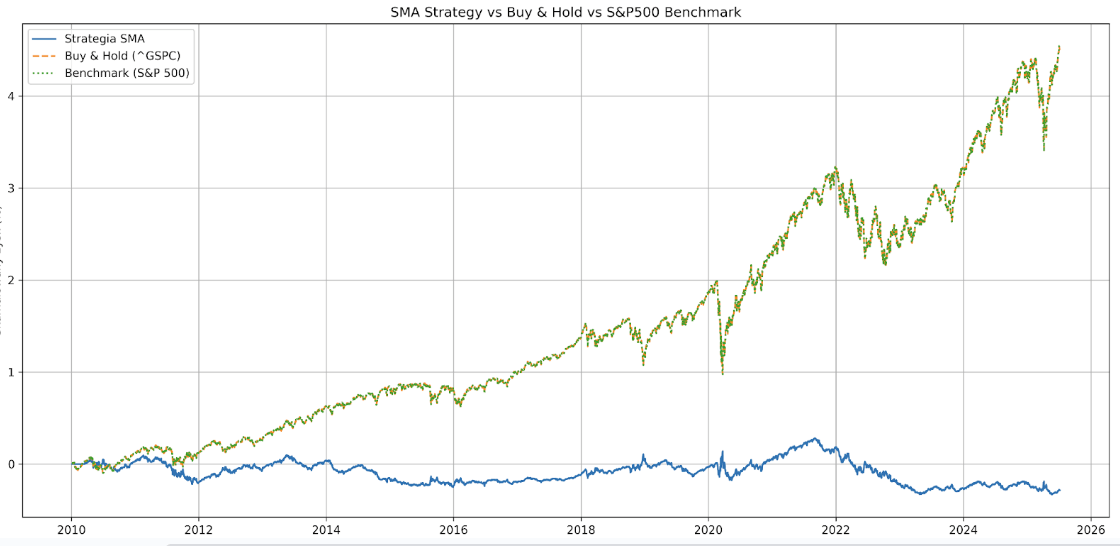
Domyślnie, strategia korzysta ze średnich kroczących o okresach 20 i 50:
Możemy wydłużyć te okresy do 20 i 200, 21 i 200 oraz 50 i 200, by zmniejszyć częstotliwość transakcji i porównać wyniki wszystkich wariantów na jednym wykresie.
UWAGA!
Testowanie różnych wariantów średnich kroczących ma na celu znalezienie najbardziej skutecznych ustawień. W realnych warunkach może to doprowadzić do przesadnego dopasowania strategii do danych testowych, na których konkretne ustawienia działają najlepiej (tzw. Overfitting) i złych wynikach strategii w rzeczywistym handlu. By tego uniknąć, traderzy zwykle stosują optymalizację Walk-Forward, polegającą na etapowej weryfikacji strategii na kolejnych fragmentach danych.
Tutaj zaczynają się schody, ponieważ użytkownik który nie rozumie kodu generowanego przez LLM, może mieć spory problem z wykonaniem takiego zadania. Chat podczas rozbudowy kodu niekiedy generuje błędy logiczne, a poproszony o ich poprawienie na podstawie dokładnego komunikatu danego błędu, popełnia nowe błędy.
Jeśli mamy szczęście – w końcu trafi na właściwe rozwiązanie. Jeśli nie mamy – nie trafi na nie nigdy.
W tym przypadku błąd był prosty i Chat wyeliminował go po kilku próbach. Wgenerował nowy kod z kilkoma strategiami różniącymi się długością średnich kroczących. Obok tego otrzymał polecenie zaimplementowania dodatkowych statystyk dla każdej z nich – maksymalne obsunięcie kapitału, roczną zmienność, Sharpe i Sortino Ratio, liczbę transakcji oraz średni czas trzymania pozycji. Zasymulowano też koszty transakcyjne w wysokości 0.1%. Z wszystkim tym poradził sobie nieźle.
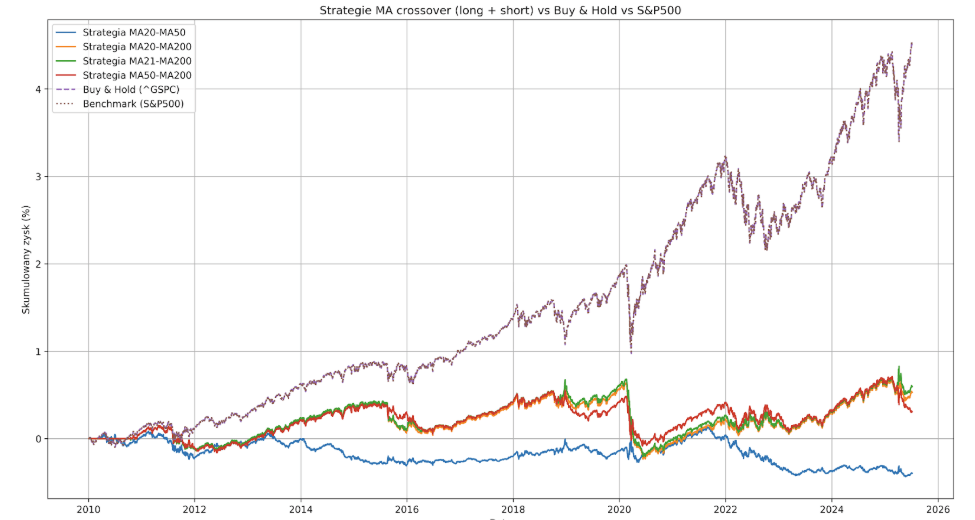
Wyniki są już wyraźnie lepsze. Bazowa strategia MA20-MA50 nadal generuje stratę – tym razem w wysokości 39.61%, ze względu na wysoką częstotliwość transakcji (169) i związane z nią koszty. Najlepsze okazały się warianty MA20-MA200 oraz MA21-MA200, które wygenerowały 52.99 i 59.48% zysku (przy zaledwie 33 transakcjach). To tyle z dobrych wieści – zysk niemal każdej ze strategii okupiony był maksymalnym obsunięciem kapitału w wysokości >50%. Wyjątkiem jest MA50-MA200, w której Max Drawdown wyniósł -40.83% (dała ona jednak tylko 30.64% zysku).
Gwoździem do trumny jest tu oczywiście sam S&P500, który w tym samym okresie dał 449.87% zwrotu, przy maksymalnym obsunięciu -33.92%. Tak, jak można się było spodziewać – żadna ze strategii opartych na średnich kroczących nie okazała się opłacalna.
Ostatnią rzeczą, której spróbujemy, jest wyeliminowanie pozycji krótkich. Średnie kroczące będą więc działać jedynie jako filtr, który pozwoli nam zamknąć pozycję long przy sygnale do sprzedaży, co być może pozwoli nam przeczekać okresy spadków na S&P500 i ograniczyć obsunięcia kapitału.
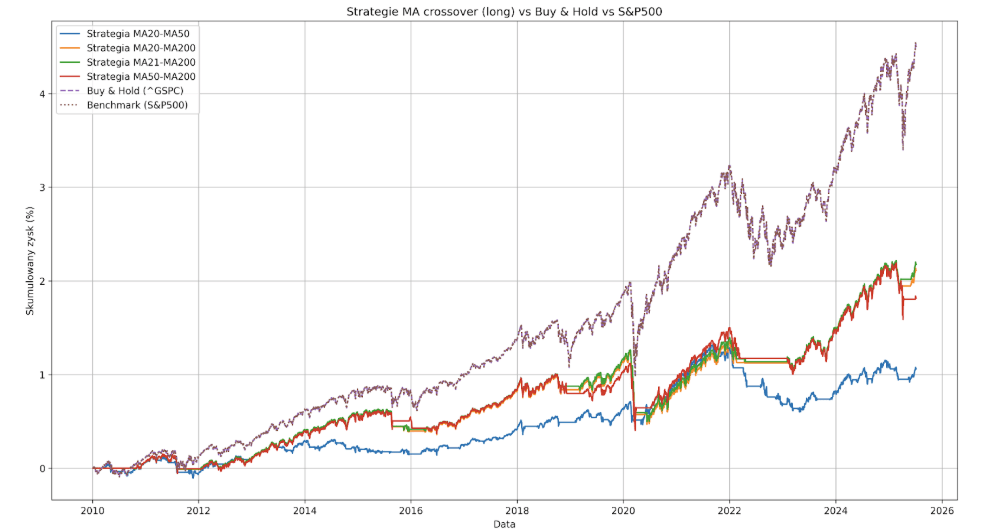
Jak widać, jest jeszcze lepiej. Generująca dotychczas starty strategia MA20-MA50 zdołała osiągnąć 105.99% zysku przy Max Drawdown rzędu -30.84%. Wariant z najlepszym wynikiem to wciąż MA21-MA200 (217.59%). Przeciętne obsunięcie kapitału w każdej ze strategii kręci się teraz w okolicach -30%, co jest wynikiem delikatnie lepszym, niż w przypadku S&P500. Oprócz tego zmieniło się jednak niewiele. Topowy system nadal generuje zaledwie niespełna połowę zwrotu indeksu (217.59% vs 449.87%), czyli korzystanie z niego nie ma sensu.
Nie można też zapominać, że strategie nadal są testowane na zyskującym na wartości w długim terminie indeksie S&P500, dlatego osiąganie jakichkolwiek zysków nieszczególnie dziwi. Przecięcia średnich są jednak bardzo popularne wśród traderów rozgrywających pary walutowe, które fluktuują, rzadziej wpadając w dłuższe trendy.
Przechodzimy więc na parę EURUSD, włączamy pozycje krótkie i tu strategie oparte na MA pokazują swoją prawdziwą twarz.
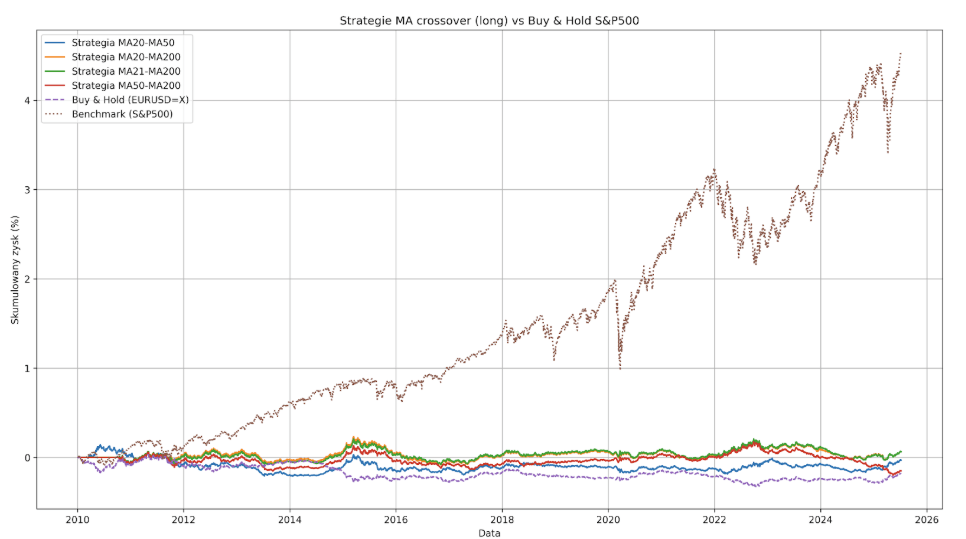
Max Drawdown w przypadku najgorszej z nich wynosi ponad 35%, zaś zysk wygenerowany przez najlepszą z nich to zaledwie 6.34% i najprawdopodobniej jest to zysk całkowicie przypadkowy.
Trzeba przyznać, że ChatGPT może być dla początkujących bardzo użytecznym narzędziem, ponieważ przy minimum wiedzy technicznej, ograniczającej się do umiejętności korzystania z notesu Jupyter Notebook, faktycznie może udowodnić, że promowane w internecie systemy oparte na prostych wskaźnikach nie działają. A jeśli działają, generują wyniki, które nawet nie zbliżają się do bicia benchmarków. Wówczas łatwo dojść do wniosku, że zamiast bawić się w trading, rozsądniej będzie po prostu kupić S&P500.
Ostatni test ma miejsce na rynku Bitcoina.
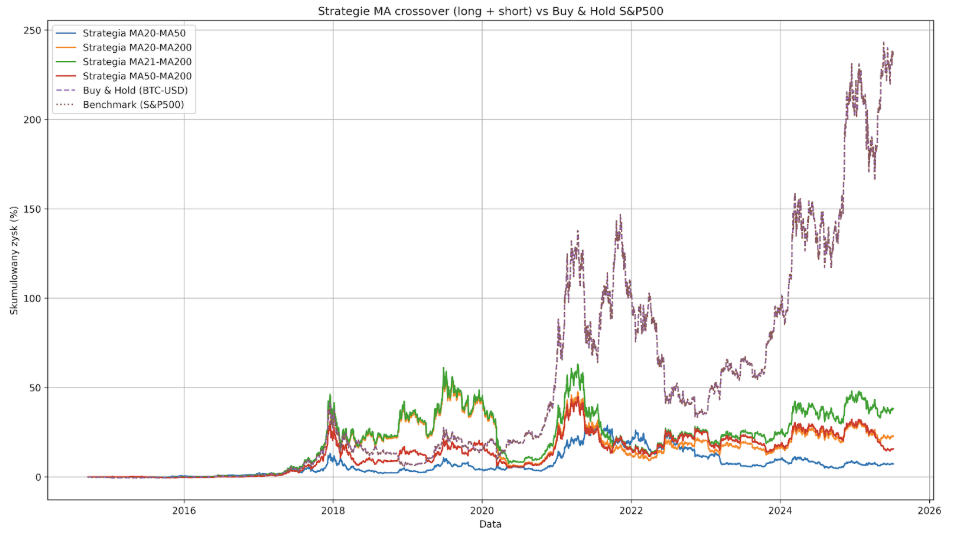
Być może ze względu na to, że BTC jest rynkiem młodym i jeszcze do niedawna był zdominowany przez traderów detalicznych, strategie tradingowe long/short oparte na średnich kroczących generują tu jakieś zyski. Max Drowdown w przypadku każdej z nich jest jednak porównywalny z samym Bitcoinem i przekracza 80%, przy czym profity są raczej mizerne.
Buy&Hold Bitcoina od Września 2014 roku dała 23 614% zysku, kiedy najlepsza z testowanych strategii w tym samym okresie wypracowała zysk zaledwie 3805%. To wynik ponad 6 razy gorszy przy takich samych obsunięciach kapitału.
Jak w przypadku S&P500, pozostaje nam sprawdzić opcję Long Only, która być może pozwoli nam poprawić wyniki i zmniejszyć Max Drawdown.
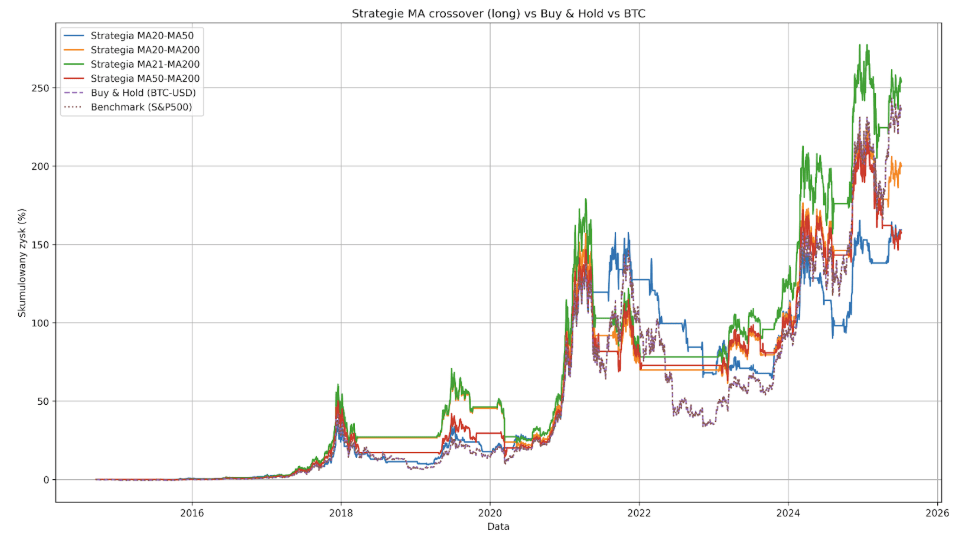
W tym przypadku, strategia MA21-MA200 zdołała pobić wynik Bitcoina (25416% vs 23646%) osiągając przy tym mniejszy Max Drawdown (-66% vs -83.40%). Problemem jest jednak minimalna liczba transakcji (21), mająca miejsce w ostatniej dekadzie mania spekulacyjna na Bitcoinie oraz jego wiek. Trudno powiedzieć, czy relatywnie dobre wyniki tak prostych strategii wynikają z ich realnej wartości, czy raczej z niedojrzałości kryptowalut oraz obserwowanej od jakiegoś czasu wrażliwości na warunki ekonomiczne i tendencji do wzrostów wraz z amerykańskimi indeksami.
Strategia dla średnio-zaawansowanych: klasyczne poziomy RSI
Do sprawdzenia zostały dwa systemy – średnio zaawansowany i zaawansowany.
Pierwszy z nich oparty jest na wskaźniku RSI. Jeśli wartość RSI jest mniejsza niż 30, rynek zostaje uznany za wyprzedany i otwieramy pozycję długą. Jeśli jest większa niż 70, uznajemy rynek za wykupiony i otwieramy pozycję krótką.
Strategia oryginalnie napisana przez ChatGPT domyślnie trzyma pozycję tylko przez jeden dzień, dlatego poprosiłem model o jej rozbudowanie o podstawowy risk management. Take Profit został ustawiony na poziomie ATR x2, a Stop Loss – na ATR x3.
Jednocześnie, był to chyba najciekawszy z przypadków, ponieważ bot popełnił przy nim błąd logiczny, który całkowicie przekreślał wynik backtestingu. Przy SL na poziomie ATR x 1.5 i TP równemu ATR x3, czyli przy stosunku RRR 1:2, strategia biła wyniki indeksu S&P 500 na głowę, generując kilkukrotnie większy zysk. Z kolei przy wyłączeniu pozycji krótkich oraz Stop Lossa i Take Profit na poziomie ATR x 2… zbankrutowała. Mimo, że ze względu brak dźwigni i otwieranie tylko longów na S&P500, który długoterminowo rośnie, powinna cokolwiek zarobić.
Po przyjrzeniu się programowi okazało się, że ChatGPT, zamiast liczyć zysk/stratę danej pozycji po jej zamknięciu, po utworzeniu każdej świecy dodawał jej zwrot do serii Returns, traktując go jako osobną transakcję. W ten sposób nie miało znaczenia, że pozycja długa, przy braku stop lossa, w dołku straciła x%, ale w końcu wyszła na plus. Każde dzienne obsunięcie ceny kod dopisywał do zaksięgowanych strat.
Wadliwe linijki zostały wyeliminowane, a wyniki znowu stały się przewidywalne. Od 2010 roku, benchmark osiągnął 452%, a nasza strategia w wersji long/short z RRR 1:2: -42.55%. Przy starcie w roku 1990, strata wyniosła już -66.64%.
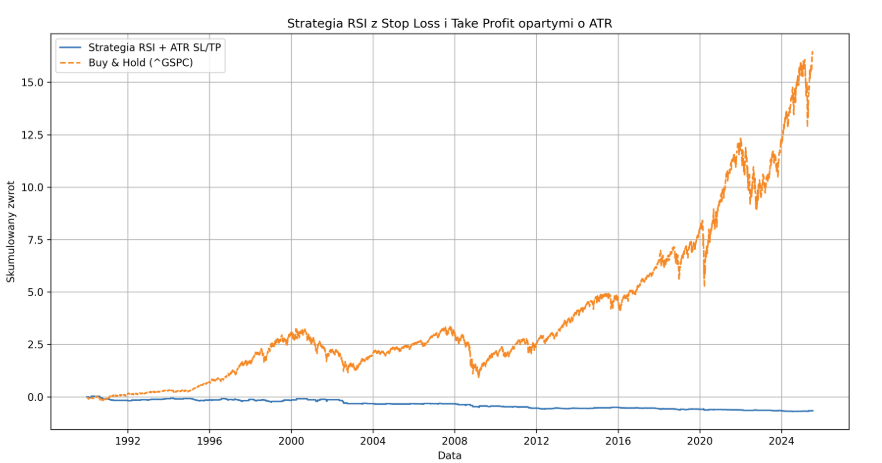
Warianty long-only to kolejno -16.43 i -46.96%. Po odwróceniu RRR na 2:1 (2j straty za 1j zysku), wyniki lekko się poprawiły: 8.14% od roku 2010 i -28.64 od roku 1990. Pozostało przetestować wersję, która często zarabia grosze i rzadziej traci znaczące kwoty (z RRR rzędu 12:1). Zwrot od 1990 roku to tutaj 9%, a od 2010: -11.66%.
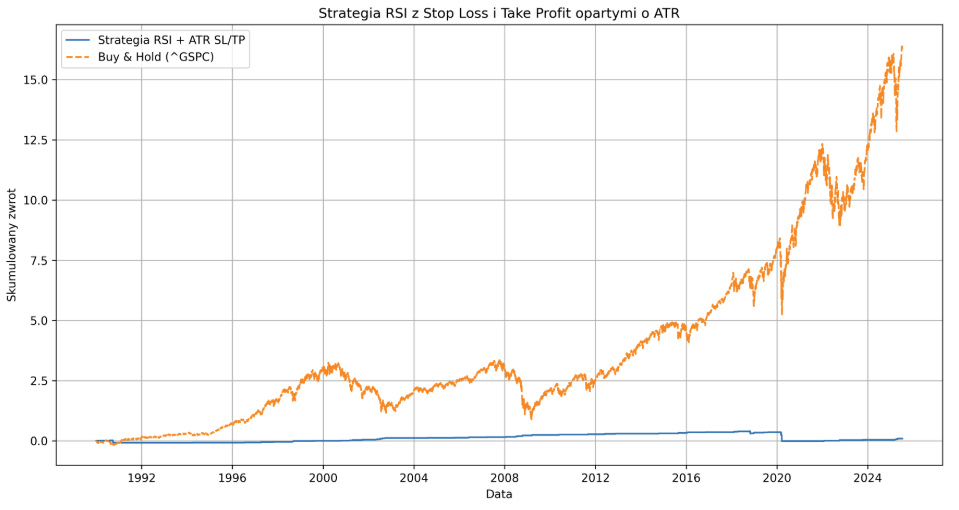
Prawdziwą katastrofą strategia okazała się na rynku Bitcoina. W wersji long + short i RRR 1:2 od 2010 roku straciła 89% kapitału. Na nic zdały się modyfikacje SL i TP, które jedynie ograniczyły drawdown. Ze względu na historyczne wzrosty BTC, pomogło wyłączenie shortów przy RRR 2:1: 436.19% oraz RRR 1:1: 1024.37%.
Z kolei na parze EURUSD, wyniki kręciły się wokół -18%.
Strategia dla “zaawansowanych”: momentum i wskaźnik ATR
Wygenerowana przez ChatGPT strategia zaawansowana także okazała się stratą czasu. System wykorzystuje wskaźnik ATR do filtrowania zmienności i na tej podstawie klasyfikuje stan, w którym znajduje się rynek. Jeśli zmienność instrumentu jest statystycznie niska, a jego cena rosła na przestrzeni ostatnich 10 dni, strategia otwiera pozycję długą.
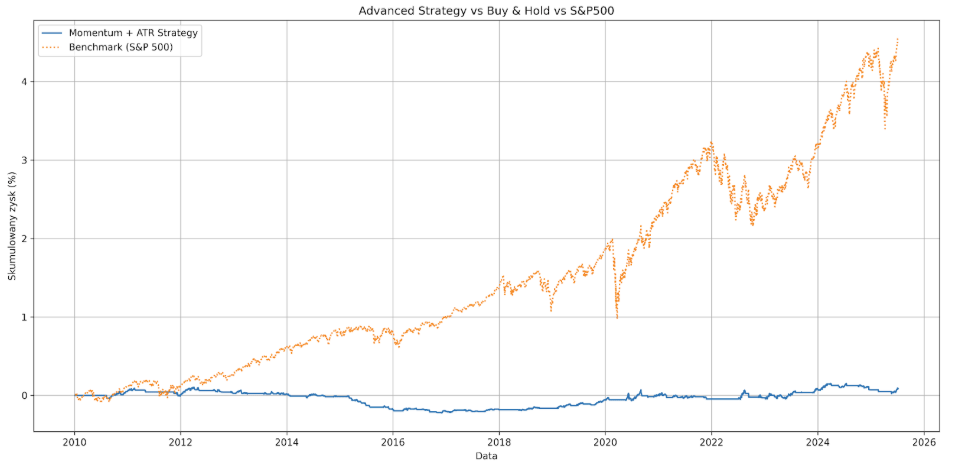
Pozwoliło to ograniczyć Max Drawdown do 8.52%, jednak jak widać na wykresie, system pominął ogromną część fazy wzrostów na S&P500, przez niemal 3 lata znajdując się pod kreską. Koniec końców, wygenerował symboliczny zwrot 8.5%, który prawdopodobnie był przypadkowy i wynikał z niewielkiego sampla.(315 transakcji i 15 lat z życia rynku).
Można to zresztą sprawdzić, zmieniając datę startową z roku 2010 na 1990.
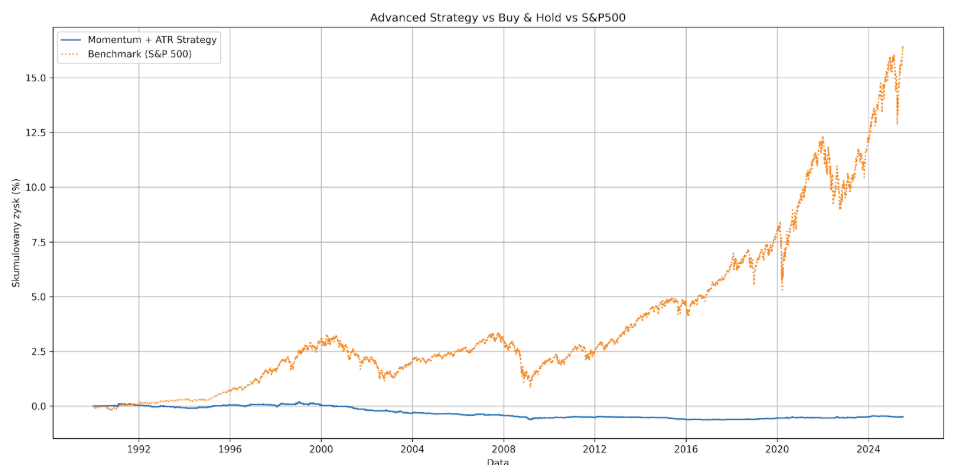
Teraz, zamiast niewielkiego zysku, widzimy niemal 48% straty.
Strategie z ChataGPT a realny backtesting
Żadna ze strategii nie wygenerowała zadowalających wyników, ale nie to było największym problemem, a fakt, że ChatGPT nie naprowadzał użytkownika na dobre tory, proponując poważniejszy backtesting. Nie ostrzegał go przed poślizgiem cenowym w realnych warunkach, overfittingiem, który może sprawić, że dobre wyniki strategii w testach rozlecą się w handlu na żywo. Nie zaproponował podziału danych na in-sample/out-of-sample (dane treningowe i testowe), optymalizacji, walidacji Walk-Forward czy metody Monte Carlo, pozwalającej wygenerować różne permutacje krzywej kapitału, którą wygenerował system.
Być może to przypadek lub problem dałoby się naprawić za pomocą lepszych, bardziej szczegółowych poleceń. Rzecz jednak w tym, że trader, który oczekuje od modelu wygenerowania gotowej strategii, nie do końca rozumie kod, który otrzymuje i nie posiada wiedzy na temat poprawnego backtestingu, prawdopodobnie nie będzie wiedział, o co zapytać i jakie polecenia wydać modelowi. A to oznacza, że ChatGPT jest czymś w rodzaju wyszukiwarki Google na sterydach – narzędziem dla kogoś, kto doskonale wie, czego szuka. Model nie poprowadzi nas za rękę i nie zbuduje za nas zarabiającego systemu.
“Prawdziwa” sztuczna inteligencja na giełdzie
W rzeczywistości, z LLMów w tradingu korzysta się podczas przetwarzania newsów finansowych w celu określenia sentymentu w mediach i niewiele ponad to. Jeśli chodzi o algorytmy AI wykorzystywane w pracy z danymi finansowymi, często są to modele takie, jak LSTM (Long-Short-Term-Memory), czyli sieci neuronowe zaprojektowane do przetwarzania i przewidywania sekwencji danych, dzięki zdolności do “zapamiętywania” informacji przez dłuższy okres.
Ze względu na wrażliwość takich modeli na overfitting, czyli zbyt dużą zależność od danych treningowych, traderzy niekiedy wybierają też Random Forest- algorytm oparty na tzw. drzewach decyzyjnych, który dzięki losowej selekcji danych i cech buduje wiele niezależnych modeli (tytułowy “Forest” – “las”), a następnie agreguje ich prognozy, co pozwala ograniczyć ryzyko przeuczenia.
Co ważniejsze, ceny instrumentów finansowych zależą od ogromnej liczby czynników i zawierają dużo szumu, dlatego algorytmy rzadko kiedy je prognozują. Częściej starają się przewidzieć zmienne, które mogą wpłynąć na cenę. W ten sposób, trader na rynkach akcji może wykorzystywać AI np. do przewidywania wyników sprzedażowych danego przedsiębiorstwa, a trader par walutowych – do prognozowania wartości wskaźników ekonomicznych.
Próby trenowania modeli na historycznych cenach, szczególnie w domowych warunkach i z pomocą ChataGPT, w najlepszym wypadku skończą się stworzeniem strategii, która nauczy się danych treningowych, jednak przestanie radzić sobie poza tym samplem i w handlu live, bo “wzorce” które rozpoznała okażą się szumem rynkowym.
ChatGPT powinien być więc traktowany jako asystent, który przyśpieszy pracę, ale nie wykona jej za nas. Na pewno nie jest to magiczne pudełko wypluwające strategie bijące wyniki benchmarków, a powód jest bardzo prosty – LLM nie myśli, ale udaje myślenie, wykorzystując statystykę.
Jak naprawdę działa Chatbot?
Wszystkie LLMy w uproszczeniu spełniają jeden warunek: są statystycznymi modelami treści, na których zostały wytrenowane i przewidują następne słowo w sekwencji. Generują coś, co wygląda na twór rozumnego bytu, jednak wygląda tak tylko dlatego, że teksty, na których je uczono, zostały stworzone przez człowieka.
W rzeczywistości ich budowa jest bardziej skomplikowana i opiera się na algebrze liniowej. Model nie przewiduje bowiem słów w naszym rozumieniu, a tzw. tokeny, czyli zbitki znaków. Dodatkowo, tokeny te są w rzeczywistości wartościami liczbowymi (wektorami) w macierzy (tzw. tensorze). W ten sposób model wykonuje operacje na wektorach reprezentujących różne fragmenty tekstu, ucząc się na ogromnych zbiorach danych przewidywania sekwencji tokenów w różnych kontekstach. Za konwersję tokenów na wektory w matrycy (tzw. “embeddings”) odpowiada Transformer.
Np. w poniższym przykładzie widzimy fragment tensora reprezentującego proste zdanie: “Kot leży na dywanie”.
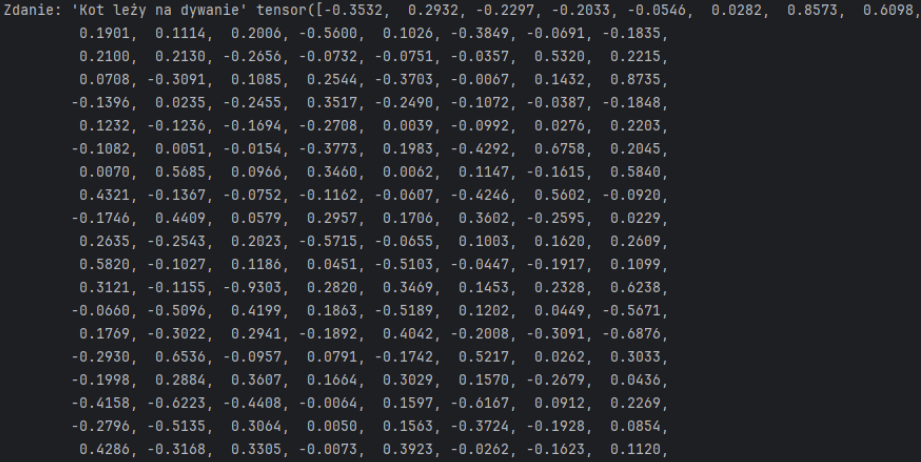
Właśnie dlatego niektórzy nazywali chatboty “stochastycznymi papugami”. LLM w działaniu nieco taką skomplikowaną papugę przypomina – powtarza słowa, których nie rozumie.
Dla tradera, który chciałby, żeby chatbot napisał mu gotową strategię i który, co gorsza, nie potrafi programować lub rozpisywać logiki swoich własnych pomysłów, ma to ogromne konsekwencje. Jeśli poprosimy LLM o napisanie systemu tradingowego, model ten odwoła się do kodu, na którym został wytrenowany. Jako że większość strategii dostępnych publicznie (które posłużyły jako dane treningowe) nie ma szans na bicie rynku (czyli korzystanie z nich nie ma sensu), otrzymamy bezwartościowy kod, który najpewniej nie osiągnie wyników lepszych, niż przypadkowa strategia z GitHuba napisana przez człowieka. A jeśli osiągnie wyniki podejrzanie dobre, prawdopodobnie jest wadliwy.




, Ukrainy (NSSMC), Irlandii (CBI), Hong Kongu (SFC), Nowej Zelandii (FMA) i Kanady (ASC, AMF) | Kwiecień 2025 #2")








